|
|
||||||||||
Nine Steps Predictive Modeling Guide for Risk ManagementDeveloping and deploying predictive models is not a trivial job. It requires a methodical approach. In this page, nine step quick guides for of predictive model development are described. YouTube Tutorial Videos: Neural Network ModelingSee YouTube videos on Neural network modeling for risk management. 1. Data Preparation: Data Cleaning and TransformationThe first step to predictive modeling involves data cleaning and transformation. Data may contain bogus values, synonymous values, outliers, etc. Those values need to be standardized and cleaned. In addition, values may need to be transformed into new variables. This process is called feature extraction. Note that it is recommended to clean and transform data from database systems as there are many SQL features available for this. In addition, CMSR RME-EP rule engine can be used to clean and transform data. 2. Import Data into CMSR StudioOnce data is cleaned and transformed, the next step is to import data into CMSR Data Miner / Machine Learning / Rule Engine Studio. Imported data will be used for variable analysis and predictive modeling. 3. Independent Variable Relevancy Analysis / Principal Component AnalysisOnce data is imported into CMSR Studio, variables are analysed to determine whether certain variables contain information that can predict customer tendencies. Confusion map chart and categorical bar/histogram charts and correlation analysis tools are used. For more, read Variable Relevancy and Factor Analysis. 4. Predictive ModelingOnce relevant variables are identified, neural network predictive models can be configured and trained using data imported into CMSR Studio. Only those variables identified as relevant are used in modeling to reduce the risk or overfitting. Multiple models with differing configurations may be used. Testing of model accuracy is performed using (historical) test data stored in database. For more on predictive modeling, please read;
5. Model Integration - AggregationMultiple predictive models are integrated as single models using RME-EP (Rule-based Model Evaluation - Event Processing) Rule Engine. Integration can take various forms such as maximum, minimum, average, etc. Those combined score values are tested using historical data (in database) and analysed. 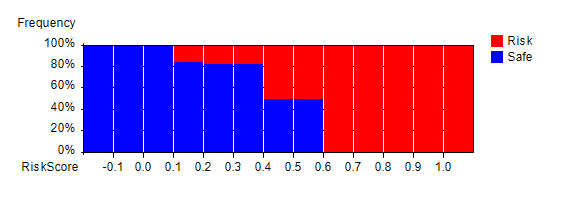
6. Model Integration - ClassificationNext step model integration may involve classification. Predicted values from neural networks are hard to understand for casual users. Those numbers are translated into more easily understood vocabularies such as very high risk, high risk, medium risk, low risk, etc. This classification is done with RME-EP. RME-EP models need to be tested for accuracy with historical test data in database. 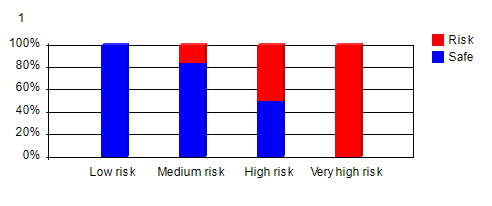
7. Preparing Model DocumentationsOnce models are integrated and tested, end-user model documentations are prepared. Model documentations are HTML files that can include charts relating to models. Model documentation should contain information what end-users will need to know. 8. Deployment on MyDataSayModels along with model documentations can be deployed on Android devices using MyDataSay Android App. MyDataSay can be served as trial before deploying on Web. 9. Web and Database IntegrationModels along with model documentations can be deployed on web using Rosella BI Server on Java/Jakarta EE Application Server. BI server provides database and other web application integration using JSP programs. In addition, CMSR can generate program function source codes in 10 different programming languages. Program source codes can be included in all major programming languages. For more on predictive modeling, please read;
|
|
|||||||||