|
|
||||||||||
Clustering and SegmentationSegmentation is the process that groups similar objects together and forms clusters. Thus it is often referred to as clustering. Clustered groups are homogeneous within and desirably heterogeneous in between. The rationale of intra-group homogeneity is that objects with similar attributes are likely to respond somewhat similarly to a given action. This property has various uses both in business and in scientific research. Self Organizing Maps (SOM) and Competitive LearningSelf Organizing Maps (SOM), also known as Kohonen Feature Maps, were developed to simulate the way that vision systems work in our brain. Organizations constructed with SOM are very useful in clustering data. It can automatically learn patterns present in data. SOM is based on Neural Network. It is noted that neural networks do not suffer greatly from the limitations discussed above. SOM uses competitive learning techniques to train networks (or to learn patterns). It is often referred to as "Winner takes all strategy", since nodes compete among themselves to display the strongest activation to a given data. Neural ClusteringCMSR provides a neural clustering procedure that is based on SOM. Neural clustering can be best explained with the figures shown below. In the figures, objects are placed into two dimensional grid cells. There are 81 cells from 9 rows and 9 columns. Note that some cells are empty with no members. Each cell contains most similar objects, i.e., having many similar properties. Objects in neighboring (or nearby) cells are also similar in nature. Closeness of cell distance indicates high degree of similarity. Neural clustering exhibits the following advantages;
Segment AnalysisIn the left figure, colored circles are pie charts representing distribution for combination of gender and race. Notice that all cells contain objects of the same single type. Furthermore, nearby cells of the same type objects are clustered together. An example of perfect clustering! The middle figure shows histograms for a numerical variable. You will notice that nearby cells have similar distributions. The right is all-in-one distribution charts for a specific cell segment. 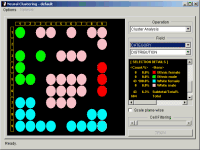
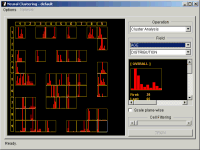
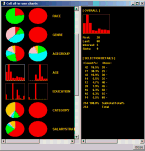 Neural clustering is robust in detecting patterns and organizes them in a way that provides powerful cluster visualization, as shown in the above figures. This is extremely useful with marketing and business data. The following is another example of neural clustering. This example is based two numerical variables. You can easily find this type of clustering in scientific research. Notice that how well neural clustering works both numerical and categorical data. 
Segmentation Variable Selection MethodsAlthough neural clustering can automatically adjust variable weights, it is often desirable to work only with variables of significant importance. Limiting to such variables can generate segments with simple and clean profiles. It is noted that careful segmentation-target variable selection is essential in predictive segmentation modeling. Unlike standard predictive modeling, predictive segmentation modeling relies on modeler's manual selection of predictive variables. Otherwise, segmentation may not induce models that show predictive power. Identification of significant variables can be very difficult without proper tools. CMSR link analysis and predictive neural network can be used for analyzing variable's significance. It is noted that selection of segmentation variables using link analysis and/or predictive neural network assures that segmentation results will have predictive power. For more on segmentation variable selection methods, read Link Analysis. For more about customer segmentation, please read Customer Segmentation. Data Mining Tools for SegmentationCMSR Data Miner supports segmentation tools based on neural networks. For software information and downloads, please read CMSR Data Miner. |
|
|||||||||