|
|
||||||||||
Rule Engine with Machine Learning, Deep Learning, Neural NetworkRule Engine and Machine Learning are often viewed as competing technology. But this view is not correct. Rule Engine and Machine Learning can be incorporated together to become a very powerful platform. For example, Deep Learing refers structured multilayer neural network models. Rule Engine can be used to glue multiple neural networks to work as a single powerful model seamlessly, thus implementing structured neural networks which are Deep Learning Models. RME-EP (Rule-based Model Evaluation with Event Processing) is a very powerful expert system shell rule engine, incorporating predictive modeling by machine learning algorithms, such as neural network, self organizing maps, decision tree, regression, time series, statistical functions, and so on. It combines rule based "forward-inference" reasoning with predictive modeling by machine learning. It provides a powerful platform for structured Deep Learning. SQL-like Rules for Easy LearningRME-EP has been developed to use SQL-like expressions which can be learnt by users and domain experts very easily and quickly. Non-IT professional users can write RME-EP expert system rules by themselves without IT professional help. RME-EP opens a new era for business users and domain experts. Note that SQL users can learn RME-EP very quickly! Predictive Modeling by Machine Learning for Deep LearningThe core concept of RME-EP is Rule-based (Predictive Machine Learning) Model Evaluation. RME-EP incorporates predictive models with logical inferrence including many logical and mathematical functions of SQL-99. By incorporating advanced predictive models into rule engine, RME-EP provides a superb platform for advanced rule-based expert systems and deep learning. RME-EP supports the following machine learning based predictive models;
(Example) Deep Learning Risk Modeling by Rule Engine and Machine LearningThe following is a RME-EP Deep Learning example for risk scoring. This is an extension of predictive modeling by machine learning described in the following links;
The following figure shows the deep learning process of this example model;
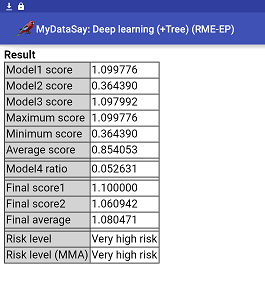
In the following codes, in the begining, variables are declared. Rule 1, 2 and 3 evaluate first three models and store on variables "Model1 score", "Model2 score", "Model3 score", respectively. Rule 4, then, computes maximum, minimum and average values of these three models. Rule 5 and 6 evaluate second tier integration models "Model4" and "Model5", using three model output values plus maximum, minimum and average values. Final result scores will be averaged and stored on "Final average". Based on "Final average" and Max/Min/Avg values, risk levels are verbalized by Rule 8 and 9. It is noted that this model incorporates neural network and decision rules as a single RME-EP model. It is a Decision Support Expert System on a Model. The following is a screenshot of of this deep learning model output on MyDataSay Android Application.
The following is a coding of this model;
/*
* This model is an example of deep learning. Three neural models are
* evaluated. Then maximum, minimum and average of three neural network
* outputs are computed. Then, these six values are fed to Model4 and
* Model5 models to produce final scores. Then final average of final scores
* is computed. Finally, final average as well as max/min/avg values are used to
* classify into verbal class names.
*
*/
// declare runtime options;
DECLARE OPTIONS EXPLICIT,ERRORNULL,MAXFIRE(0);
// DECLARE OPTIONS USEBETWEEN('2017-1-1', '2017-12-31');
// define input data fields and values in appearing order;
DECLARE Gender AS STRING INPUT VALUES IN GENDER OF Model1;
DECLARE Race AS STRING INPUT VALUES IN RACE OF Model1;
DECLARE Jobpost AS STRING INPUT VALUES IN JOBPOST OF Model1;
DECLARE CLASSIFICATION1 AS STRING INPUT VALUES IN
CLASSIFICATION1 OF Model1;
DECLARE EDUCLEVEL AS STRING INPUT
VALUES IN EDUCLEVEL OFModel1;
DECLARE AGEGROUP AS STRING INPUT
VALUES IN AGEGROUP OF Model1;
DECLARE Salary AS INTEGER INPUT;
// define output fields in appearing order;
DECLARE "Model1 score", "Model2 score", "Model3 score"
AS REAL OUTPUT;
DECLARE "" AS STRING OUTPUT INITIAL VALUE '';
DECLARE "Maximum score", "Minimum score", "Average score"
AS REAL OUTPUT;
DECLARE " " AS STRING OUTPUT INITIAL VALUE '';
DECLARE "Final score1", "Final score2", "Final average"
AS REAL OUTPUT;
DECLARE " " AS STRING OUTPUT INITIAL VALUE '';
DECLARE "Risk level", "Risk level (MMA)" AS STRING OUTPUT;
/*
* DATA MODEL EVALUATION
*/
RULE 1: // evaluate model 1;
IF TRUE THEN
SET "Model1 score" AS PREDICT(Model1) USING(
GENDER AS Gender,
RACE AS Race,
JOBPOST AS Jobpost,
CLASSIFICATION1 AS CLASSIFICATION1,
EDUCLEVEL AS EDUCLEVEL,
AGEGROUP AS AGEGROUP,
SALARY AS Salary
)
END;
RULE 2: // evaluate model 2;
IF TRUE THEN
SET "Model2 score" AS PREDICT(Model2) USING(
GENDER AS Gender,
RACE AS Race,
JOBPOST AS Jobpost,
CLASSIFICATION1 AS CLASSIFICATION1,
EDUCLEVEL AS EDUCLEVEL,
AGEGROUP AS AGEGROUP,
SALARY AS Salary
)
END;
RULE 3: // evaluate model 3;
IF TRUE THEN
SET "Model3 score" AS PREDICT(Model3) USING(
GENDER AS Gender,
RACE AS Race,
JOBPOST AS Jobpost,
CLASSIFICATION1 AS CLASSIFICATION1,
EDUCLEVEL AS EDUCLEVEL,
AGEGROUP AS AGEGROUP,
SALARY AS Salary
)
END;
/*
* COMPUTE MAXIMUM / MINIMUM / AVERAGE
*/
RULE 4: // compute max/min/avg;
IF TRUE THEN
{
SET "Maximum score"
AS MAX("Model1 score", "Model2 score", "Model3 score");
SET "Minimum score"
AS MIN("Model1 score", "Model2 score", "Model3 score");
SET "Average score"
AS AVG("Model1 score", "Model2 score", "Model3 score");
}
END;
/*
* EVALUATE INTEGRATION NETWORKS
*/
RULE 5: // evaluate model 4;
IF TRUE THEN
SET "Final score1" AS PREDICT(Model4) USING(
Model1Score AS "Model1 score",
Model2Score AS "Model2 score",
Model3Score AS "Model3 score",
MaximumScore AS "Maximum score",
MinimumScore AS "Minimum score",
AverageScore AS "Average score"
)
END;
RULE 6: // evaluate model 5;
IF TRUE THEN
SET "Final score2" AS PREDICT(Model5) USING(
Model1Score AS "Model1 score",
Model2Score AS "Model2 score",
Model3Score AS "Model3 score",
MaximumScore AS "Maximum score",
MinimumScore AS "Minimum score",
AverageScore AS "Average score"
)
END;
/*
* COMPUTE INTEGRATION MODEL AVERAGE
*/
RULE 7: // compute average of final scores
IF TRUE THEN
SET "Final average" AS AVG("Final score1", "Final score2")
END;
/*
* FINAL CLASSIFICATIONS
*/
RULE 8: // classify risk levels with final average;
CASE
WHEN "Final average" >= 0.7 THEN
SET "Risk level" AS 'Very high risk'
WHEN "Final average" < 0.01 THEN
SET "Risk level" AS 'Low risk'
WHEN "Final average" < 0.1 THEN
SET "Risk level" AS 'Medium risk'
WHEN "Maximum score" >= 0.6 OR "Minimum score" >= 0.2
OR "Average score" >= 0.5 THEN
SET "Risk level" AS 'Very high risk'
WHEN "Maximum score" >= 0.3 OR "Minimum score" >= 0.05
OR "Average score" >= 0.2 THEN
SET "Risk level" AS 'High risk'
WHEN "Maximum score" >= 0.2 OR "Minimum score" >= 0.0
OR "Average score" >= 0.1 THEN
SET "Risk level" AS 'Medium risk'
ELSE
SET "Risk level" AS 'Low risk'
END;
RULE 9: // classify risk levels without final average;
CASE
WHEN "Maximum score" >= 0.6 OR "Minimum score" >= 0.2
OR "Average score" >= 0.5 THEN
SET "Risk level (MMA)" AS 'Very high risk'
WHEN "Maximum score" >= 0.3 OR "Minimum score" >= 0.05
OR "Average score" >= 0.2 THEN
SET "Risk level (MMA)" AS 'High risk'
WHEN "Maximum score" >= 0.2 OR "Minimum score" >= 0.0
OR "Average score" >= 0.1 THEN
SET "Risk level (MMA)" AS 'Medium risk'
ELSE
SET "Risk level (MMA)" AS 'Low risk'
END;
For more and software downloads, read CMSR Data Miner / Machine Learning / Rule Engine Studio. |
|
|||||||||