|
|
|
Home | Business Intelligence | Data Mining | Rosella DBMS | Products & Downloads | Site Map | Contact Us | |
Star SchemaStar schema is a standard technique for designing and building multi-dimensional databases in data warehousing. Star schema typically consists of a single main table and zero or more dimensional table. An instance of star schema, or a star schema dataset, is called star. It is noted that StarProbe is named after these stars. Use of star schema in data mining has the following advantages;
Flat TablesIn a simplest form, data may be organized into a flat table that consists of a set of fields (or attributes or variables) only. Fields can be divided into dimensional, aggregate or hybrid fields. Dimensional fields define dimensions of information. They contain nominal data. Aggregate fields, on the other hand, contain linear data that represent some kinds of measurement. Values of aggregate fields can be applied to aggregate functions such as sum, average, minimum, and maximum, etc. In certain cases, numerical data may behave as dimensional data (or nominal data) as well as aggregate (or linear) data. You may encounter this hybrid type quite often. For example, you may need to consider "year" as a dimension as well as aggregate (i.e., linear) information at the same time. The following is an example of flat table schema for international wholesale; 
The first four fields are dimensions. The last two fields are aggregates. Values of aggregate fields can be summarized (i.e., summed) by groups induced by values of dimensional fields. For instance, we may sum the amount by year and store, or the quantity by store, and so on. Dimensional Data ModelingThe dimensional fields, "month", "store" and "product" of the wholesale schemata, imply further information that is not shown in the schemata. For instance, "month" implies "seasons", "quarters", etc. "Store" indicates "state", "country", "region" etc. The flat table may be expanded to include all these implied fields. However, such simple expansion can lead various side effects. (Details of side effects are beyond the scope of this manual. Interested readers may consult any database textbooks.) Star schema provides a natural extension to represent such implied information. The basic idea of star schema is simple. That is to say, instead of adding additional fields into flat tables, a dimensional field can be extended with a separate auxiliary table containing implied information. For instance, we may create a table called "month" containing fields seasons, quarters, and biannual, etc. For the "store" field, a table called "store" containing state, country, region, etc., can be used. Similarly, we may extend the "product" field. The followings show this extension tables; 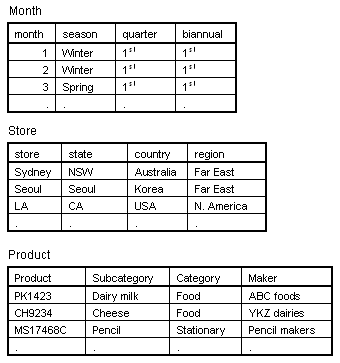
In star schema, base tables are called main (or fact) tables. Auxiliary tables are referred to as domain (or dimensional) tables. Fields with auxiliary tables can be said tabled. In another words, a star schema will consist of a main fact table and zero or more domain tables. A flat file schema is a special case of star schema where there are no domain tables. Domain tables must contain a key field that has the same property as the corresponding field of a base table. In addition, key fields must appear as the first field in domain tables. Key fields are used by the system in binding fact tables and domain tables together. In the star schema architecture, the wholesale example can be remodeled as in the following figure (Note that key fields are underlined in the figure.); 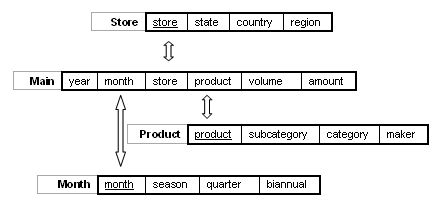
Snowflake SchemaSnowflake schema is extension of star schema. From star schema, snowflake schema decomposes dimensional tables further to remove redundancies. Net effect of this extension is Third Normal Form (3NF) schema! It is normalized schema commonly used in OLTP databases. Note that one of main advantage of star schema is performance. Generally, dimensional data is stable. In addition, joining fully decomposed data on the fly is very expensive process. Star schema takes advantage of these facts. Then why bother to employ extended star schema? Multiple Taxonomic Categorization and Flexible Rating SystemsA very powerful feature of star schema is that star schema allows multiple taxonomic categorization. This also can be used to model flexible multiple rating systems. More specifically, take the following dimensional table. It is common to see survey data containing responses based on ratings as follows. The first column is numerical values which can be used as numerical elements. The second is description of the numerical values. This categorization can be restructured in various ways as shown in the other columns. Note that this table can be used in any dimensional columns with the same rating system. This extended information will further enrich data mining results. 
|
|